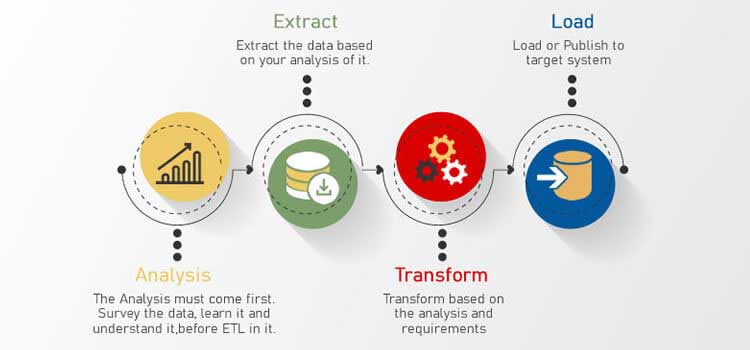
The ETL process is prone to errors and risks as the quality of source data is unknown. Data Testing holds a significant position in integration and ETL projects and it mitigates the risks of data corruption.
The risks associated with an ETL project are summarized below.
1. In most cases the quality of the data is unknown, and this can lead to missing a deliverable deadline and can cause the project to go over budget and may not meet the agreed schedule.
The best practice to mitigate this risk is to perform formal data profiling of source data prior to starting the work. At the beginning stage of scope discussions, data profiling should be executed. This will help you identify whether the source data quality can meet the project requirements or not. All inherent errors like inaccuracy, duplication, etc. can be identified and resolved before or during an ETL process. A QA resource or multiple QA resources will not be sufficient, the best practice is to implement automated data quality tools.
2. Sometimes data dictionaries are not available and the available data dictionaries can be defective. This makes it difficult for the data engineers and tech teams to interpret data at its source. The best practice to mitigate this risk it is prudent to ensure accurate and latest documentation of data models and mapping documents.
3. It happens often in ETL Project Developers and data teams find out defects in data at a later stage. To avoid this grave issue happening at a later stage of the ETL process, it is important to check data dictionaries are available and current prior to starting the work. Profiling of all data sources and target data after each ETL, cleansing, and fixing of corrupt data all are significant to ensure a smooth ETL process.
4. Complex transformations can be tricky and are not easy to test. It takes good testing skills and the right testing tools. Initial authentication of table join complexity, queries, and resulting business reports and validating the number and availability of source data fields can help resolve this issue.
5. In ETL projects there are scenarios where the data keeps growing. It is important to estimate the data volumes and in order to do so the right skill set is needed to be in place. One way of ensuring it is to load the database with the highest predictable production volumes to figure out that this much amount of data can be loaded by the ETL Process within the decided time frame.
.jpg")
6. Only the source data is not the issue. Another factor that can be a potential risk to an ETL process is the lack of potential skilled resources that can perform testing and integration. Qualified skilled resources are not easy to locate. The solution to this is to invest in the right training courses for the respective resources. Specialized data roles are required to deliver overall ETL lifecycle such as data analysts, data QA, data scientists, programmers who can code and write scripts, etc.
Wayne Yaddow has over 12 years of experience leading data migration/integration/ETL testing projects at organizations including J.P. Morgan Chase, Credit Suisse, Standard and Poor’s, AIG, Oppenheimer Funds, and IBM. Wayne has written extensively on the subject and taught IIST (International Institute of Software Testing) courses on data warehouse, ETL, and data integration testing. He continues to lead ETL testing and coaching projects as an independent consultant. Potentially there can be unwarranted many deficiencies in the Target Data after ETL.
The best practices as per Wayne Yaddow, to mitigate this risk is to make sure the following:
- Ensure that the target data sampling process is of high quality.
- Use test tools that provide for extensive data coverage.
- Choose a data sampling approach that’s extensive enough to avoid missing defects in both source and target data.
- Choose an appropriate technology to compare source and target data to determine whether both source and target are equal, or target data has been transformed.
- Verify that no data or metadata has been lost during ETL processes. The data warehouse must load all relevant data from the source application into the target according to business rules.
- Check the correctness of surrogate keys that uniquely identify rows of data.
- Check data loading status and error messages after ETL’s
- Verify that data types and formats are as specified during database design.
- Verify that every ETL session completed with only planned exceptions.
Ref: http://wyaddow.academia.edu/research#papersandresearch
Conclusion
It is easier than before to access data from different sources. Modern systems have made it possible for us to access this data from different sources easily. The true challenge comes at the time of transforming and ingesting the data and then integrating this disparate data in various formats from different data streams.
There are errors, duplication issues, and poor-quality data after ETL. These risks associated with an ETL process can be fatal. However, all these inherent risks can be mitigated by implementing a solid testing plan, skilled resources to perform the ETL, investing in the right training courses, and getting the picture right from the beginning by devising a plan based on profiling of the data.
Soft Tech Group can help you with your ETL process, data challenges, and mitigating the risks. Please feel free to Contact Us.